요약
- 트리 구조에서 하나의 노드가 자식 노드를 2개까지 가질 수 있는 트리 구조
- 포화 이진 트리와 완전 이진 트리 구조로 나뉨
- 높이에 따라 높이 균형 트리와 완전 높이 균형 트리 구조로 나뉨
- 노드 방문 순서에 따라 전위 순회, 중위 순회로 나뉨
- 트리 소멸 시 잎 구조부터 제거해야 하며 후위 순회 방식으로 제거해야
이진 트리(Binary Tree)
이진 트리란 일반 트리와 개념은 같지만, 하나의 노드가 자식 노드를 2개까지만 가질 수 있다는 점이 다르다.
이진 트리라는 이름도 자식을 둘만 가진다는 의미에서 붙어진 이름이다.
아래 그림이 이진 트리의 구조를 개념적으로 표현한 그림이다.

이진 트리의 종류
이진 트리의 가장 중요한 부분은 노드의 최대 차수가 2라는 사실이다.
즉, 모든 이진 트리 노드의 자식 수는 0, 1, 2 중 하나이다.
포화 이진 트리(Full Binary Tree)
포화 이진 트리란 잎 노드를 제외한 모든 노드가 자식을 둘씩 갖고 있는 트리 구조를 말한다.
포화 이진 트리는 잎 노드들이 모두 같은 깊이에 위치한다는 특징을 가진다.
완전 이진 트리(Complete Binary Tree)
완전 이진 트리란 잎 노드들이 왼쪽부터 차곡차곡 채워져 가는 트리 구조를 말한다.
아래 그림을 보면 잎 노드들이 왼쪽부터 채워지는 것을 볼 수 있으며, 세 트리 모두 완전 이진트리이다.
아래 그림의 트리구조 처럼 왼쪽 잎이 없는데, 오른쪽 잎이 존재하는 경우는 완전 이진트리가 아니다.
이진 트리의 상태
이진 트리는 일반 트리처럼 나무 모양의 자료를 담는 자료구조가 아닌, 컴파일러나 검색 등과 같은 알고리즘의 뼈대가 되는 특별한 자료구조이다.
특히 이진 트리를 이용한 검색에서는 트리의 노드를 가능한한 완전한 모습으로 유지해야 높은 성능을 낼 수 있다.
이진 트리의 상태를 나타내는 용어로 높이 균형 트리(Height Balanced Tree)와 완전 높이 균형 트리(Completely Height Banlanced Tree)가 있다.
높이 균형 트리
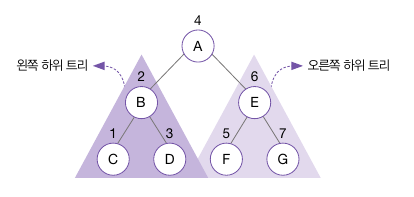
먼저 높이 균형 트리는 다음 그림과 같이 뿌리 노드를 기준으로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 2이상 차이나지 않는 이진 트리를 말한다.
완전 높이 균형 트리
완전 높이 균형 트리는 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 같은 이진 트리를 말한다.
아래 그림이 완전 높이 균형 이진 트리를 말한다.
이진 트리의 순회(Binary Tree Traversal)
순회는 간단히 말해 트리 안에서 노드 사이를 이동하는 연산을 말한다.
트리에는 데이터 접근 순서로 분류한 몇 가지 순회 패턴이 존재한다.
- 전위 순회 : 뿌리 노드부터 잎 노드까지 아래 방향으로 방문하는 순회 방법
- 중위 순회 : 왼쪽 하위 트리부터 오른쪽 하위 트리 방향으로 방문하는 순회 방법
- 후위 순회 : 왼쪽 하위 트리-오른쪽 하위 트리- 순으로 방문하는 순회 방법
전위 순회(Preorder Traversal)
전위 순회는 뿌리 노드부터 잎 노드까지 아래 방향으로 방문하는 순회 방법이다.
아래 그림이 전위 순회의 예인데, A(1) 뿌리 노드부터 시작하여 아래로 내려온다.
그리고 B(2) 왼쪽 하위 트리를 방문하고, 그 후 E(5) 오른쪽 하위 트리를 방문하는 순서이다.
이 그림에서 나타난 트리는 아래 그림과 같이 뿌리 노드, 왼쪽 하위 트리, 오른쪽 하위 트리 세 부분으로 나눌 수 있다.
왼쪽 하위 트리(B, C, D)의 뿌리 노드는 B 노드이다. 그리고 B, C, D 트리의 왼쪽 하위 트리는 C, 오른쪽 하위 트리는 D이다.
전위 순회는 이 하위 트리에서도 뿌리 노드 -> 왼쪽 하위 트리 -> 오른쪽 하위 트리 순으로 방문한다.
그래서 B를 방문한 이후 왼쪽 하위 트리인 C 노드를, 그 이후에 D 노드를 방문하는 순서이다.
이 규칙은 오른쪽 하위 트리에서도 마찬가지로 적용된다.
E 노드를 거쳐 왼쪽 하위 트리인 F, 그 이후 G 노드를 방문하는 순서이다.
전위 순회를 이용하면 이진 트리를 중첩된 괄호로 표현할 수 있다.
뿌리 노드부터 시작해 방문하는 노드의 깊이가 길어질 때마다 괄호를 한겹씩 둘러 표현한다.
위 트리는 아래의 구조로 표현할 수 있다.
(A(B(C, D))),(E(F, G)))
중위 순회(Inorder Traversal)
중위 순회는 왼쪽 하위 트리부터 오른쪽 하위 트리 방향으로 방문하는 순회 방법이다.
왼쪽 하위 트리인 C 노드(1) 부터 시작해서 뿌리 노드인 A 노드(4)를 거쳐 오른쪽 하위 트리인 F 노드(5) 순서로 방문하는 방법이다.
하위 트리부터 시작한다는 말은 트리에서 가장 왼쪽의 잎 노드부터 시작한다는 뜻이다.
이 뜻은 잎 노드에서부터 시작된 순회는 부모 노드를 방문한 후 자신의 형제 노드를 방문하는 것이다.
이렇게 해서 최소 단위의 하위 트리 순회가 끝나면 다시 그 위 단계 하위 트리에 대해 순회하는 것으로 이루어 진다.
아래 그림이 중위 순회 방법을 나타내는 그림이다.
중위 순회가 사용되는 대표 사례가 수식 트리이다.
아래 그림은 아래 수식을 트리 구조로 나타낸 그림이다.
(1 * 2) + (7 + 8)
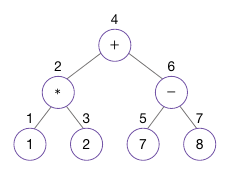
먼저 가장 왼쪽 잎인 방문하여 중위 순회 방법으로 방문하면 수식이 되는 것을 볼 수 있다.
후위 순회(Postorder Traversal)
후위(Postorder)의 반대말은 전위(Preorder)로, 말 그대로 전위 순회와 반대되는 방법이다.
즉, 후위 순회의 방문 순서는 왼쪽 하위 트리 -> 오른쪽 하위 트리 -> 뿌리 노드 순서로 방문한다.
이 순서는 하위 트리의 하위 트리, 또 그 하위 트리의 하위 트리에 대해 똑같이 적용된다.
이때 만약 잎 노드라면 방문이 중지된다.
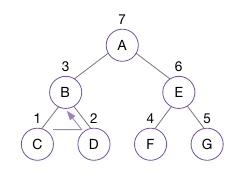
아래 그림이 후위 순회를 나타내는 그림이다.
이진 트리의 기본 연산
노드 선언
노드를 이루는 구조체로, left, right, data 필드가 존재한다.
typedef struct _Node
{
// 왼쪽 자식을 가리키는 필드
struct _Node* left;
// 오른쪽 자식을 가리키는 필드
struct _Node* right;
// 데이터를 담는 필드
char data;
} Node;
노드 생성
노드 생성을 위한 함수로, 먼저 malloc() 함수를 사용해 구조체의 크기만큼 메모리 공간을 할당한다.
할당한 메모리 공간을 newNode 포인터에 저장하고, left, right 필드를 NULL로 초기화한다.
data 필드에는 매개 변수로 받은 값을 할당하고 마지막으로 노드의 포인터를 반환한다.
Node* CreateNode(char newData)
{
// 메모리 공간 할당
Node* newNode = (Node*)malloc(sizeof(Node));
// 각 필드 초기화
newNode->left = NULL;
newNode->right = NULL;
newNode->data = newData;
// 노드의 포인터 반환
return newNode;
}
노드 소멸
노드 소멸은 free() 함수를 이용해 공간 할당을 해제한다.
void DestroyNode(Node* node)
{
free(node);
}
트리 출력
트리 출력은 전위, 중위, 후위 순회 방법을 이용해 출력할 수 있다.
전위 순회를 이용한 이진 트리 출력
전위 순회는 뿌리 노드 -> 잎 노드까지, 위에서 아래로 타고 내려온다.
void PreorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 뿌리 노드 출력
printf(" %c", node->data);
// 왼쪽 하위 트리 출력
PreorderPrintTree(node->left);
// 오른쪽 하위 트리 출력
PreorderPrintTree(node->right);
}
중위 순회를 이용한 이진 트리 출력
중위 순회는 왼쪽 하위 트리 -> 뿌리 -> 오른쪽 하위 트리 순으로 방문한다.
void InorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 왼쪽 하위 트리 출력
InorderPrintTree(node->left);
// 뿌리 노드 출력
printf(" %c", node->data);
// 오른쪽 하위 트리 출력
InorderPrintTree(node->right);
}
후위 순회를 이용한 이진 트리 출력
후위 순회는 왼쪽 하위 트리 -> 오른쪽 하위 트리 -> 뿌리 순으로 방문한다.
void PostorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 왼쪽 하위 트리 출력
PostorderPrintTree(node->left);
// 오른쪽 하위 트리 출력
PostorderPrintTree(node->right);
// 뿌리 노드 출력
printf(" %c", node->data);
}
후위 순회를 이용한 트리 소멸
트리를 생성할 때는 노드들이 어떤 순서로 생성되는지 상관 없지만, 소멸은 얘기가 다르다.
트리를 소멸할 때 반드시 잎 노드부터 제거해야 한다.
따라서 잎 노드부터 뿌리 노드로 방문하는 후위 순회를 이용하면 문제 없이 소멸시킬 수 있다.
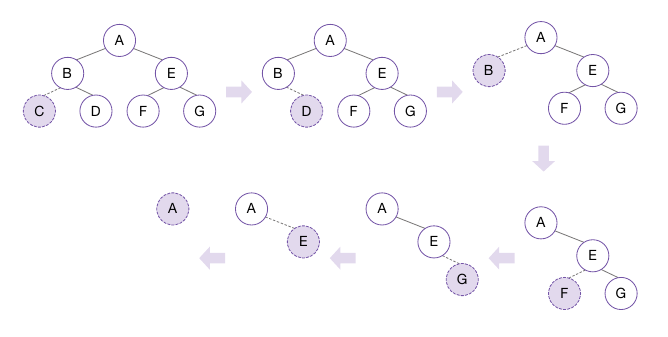
void DestroyTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
DestroyTree(node->left);
DestroyTree(node->right);
DestroyNode(node);
}
전체 예제 코드
#include <stdio.h>
#include <stdlib.h>
typedef struct _Node
{
// 왼쪽 자식을 가리키는 필드
struct _Node* left;
// 오른쪽 자식을 가리키는 필드
struct _Node* right;
// 데이터를 담는 필드
char data;
} Node;
Node* CreateNode(char newData);
void DestroyNode(Node* node);
void PreorderPrintTree(Node* node);
void InorderPrintTree(Node* node);
void PostorderPrintTree(Node* node);
void DestroyTree(Node* node);
int main()
{
// 노드 생성
Node* A = CreateNode('A');
Node* B = CreateNode('B');
Node* C = CreateNode('C');
Node* D = CreateNode('D');
Node* E = CreateNode('E');
Node* F = CreateNode('F');
Node* G = CreateNode('G');
// 트리에 노드 추가
A->left = B;
B->left = C;
B->right = D;
A->right = E;
E->left = F;
E->right = G;
// 전위 순회 방식 트리 출력
printf("Preorder Tree\n");
PreorderPrintTree(A);
printf("\n\n");
// 중위 순회 방식 트리 출력
printf("Inorder Tree\n");
InorderPrintTree(A);
printf("\n\n");
// 후위 순회 방식 트리 출력
printf("Postorder Tree\n");
PostorderPrintTree(A);
printf("\n");
DestroyTree(A);
return 0;
}
Node* CreateNode(char newData)
{
// 메모리 공간 할당
Node* newNode = (Node*)malloc(sizeof(Node));
// 각 필드 초기화
newNode->left = NULL;
newNode->right = NULL;
newNode->data = newData;
// 노드의 메모리 주소 반환
return newNode;
}
void DestroyNode(Node* node)
{
free(node);
}
void PreorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 뿌리 노드 출력
printf(" %c", node->data);
// 왼쪽 하위 트리 출력
PreorderPrintTree(node->left);
// 오른쪽 하위 트리 출력
PreorderPrintTree(node->right);
}
void InorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 왼쪽 하위 트리 출력
InorderPrintTree(node->left);
// 뿌리 노드 출력
printf(" %c", node->data);
// 오른쪽 하위 트리 출력
InorderPrintTree(node->right);
}
void PostorderPrintTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
// 왼쪽 하위 트리 출력
PostorderPrintTree(node->left);
// 오른쪽 하위 트리 출력
PostorderPrintTree(node->right);
// 뿌리 노드 출력
printf(" %c", node->data);
}
void DestroyTree(Node* node)
{
// 빈 노드일 경우
if(node == NULL) {
return;
}
DestroyTree(node->left);
DestroyTree(node->right);
DestroyNode(node);
}
실행 결과
Preorder Tree
A B C D E F G
Inorder Tree
C B D A F E G
Postorder Tree
C D B F G E A
출처 : 이것이 자료구조+알고리즘이다 with C언어
'Algorithm > 이론' 카테고리의 다른 글
| [Algorithm] C - 우선순위 큐(Priority Queue) (0) | 2022.12.10 |
|---|---|
| [Algorithm] C - 수식 트리(Expression Tree) (1) | 2022.12.04 |
| [Algorithm] C - 트리(Tree) 자료 구조 (0) | 2022.12.04 |
| [Algorithm] C - 이진 탐색 트리(Binary Search Tree) (4) | 2022.12.03 |
| [Algorithm] C++ - 소수 구하기 (제곱근, 에라토스테네스의 체) (0) | 2022.11.20 |